Working with Ollama
Learn how to connect your Ollama to Octarine to use Writing Assistant and Ask Octarine
Ollama is a simple way to run large language models on your own machine. This guide shows you how to install it, download a model, and connect it to Octarine so you can use AI features completely offline and privately.
Prerequisites
Ollama works on macOS, Windows, and Linux. Just make sure your system has enough CPU, RAM, and storage to handle the models you want to run.
Step 1: Install Ollama
Visit the Ollama official website and download the installer for your operating system.
On macOS, open the .dmg file and follow the instructions. On Windows, run the .exe and complete the wizard. If you're on Linux, check the Ollama website for instructions specific to your distribution.
Step 2: Pull a Model
After installing Ollama, you need to download a model. Open Terminal (on macOS/Linux) or Command Prompt or PowerShell (on Windows), and run this command:
ollama pull llama2
Replace llama2 with whatever model you want to use. You can find a full list of available models in the Ollama documentation.
Step 3: Start the Ollama Service
In the same terminal or command prompt, start the Ollama server:
ollama serve
This runs the server on http://localhost:11434 by default. Keep this terminal window open—you need the service running for Octarine to connect.
Step 4: Connect Ollama to Octarine
Now let's hook it up to Octarine.
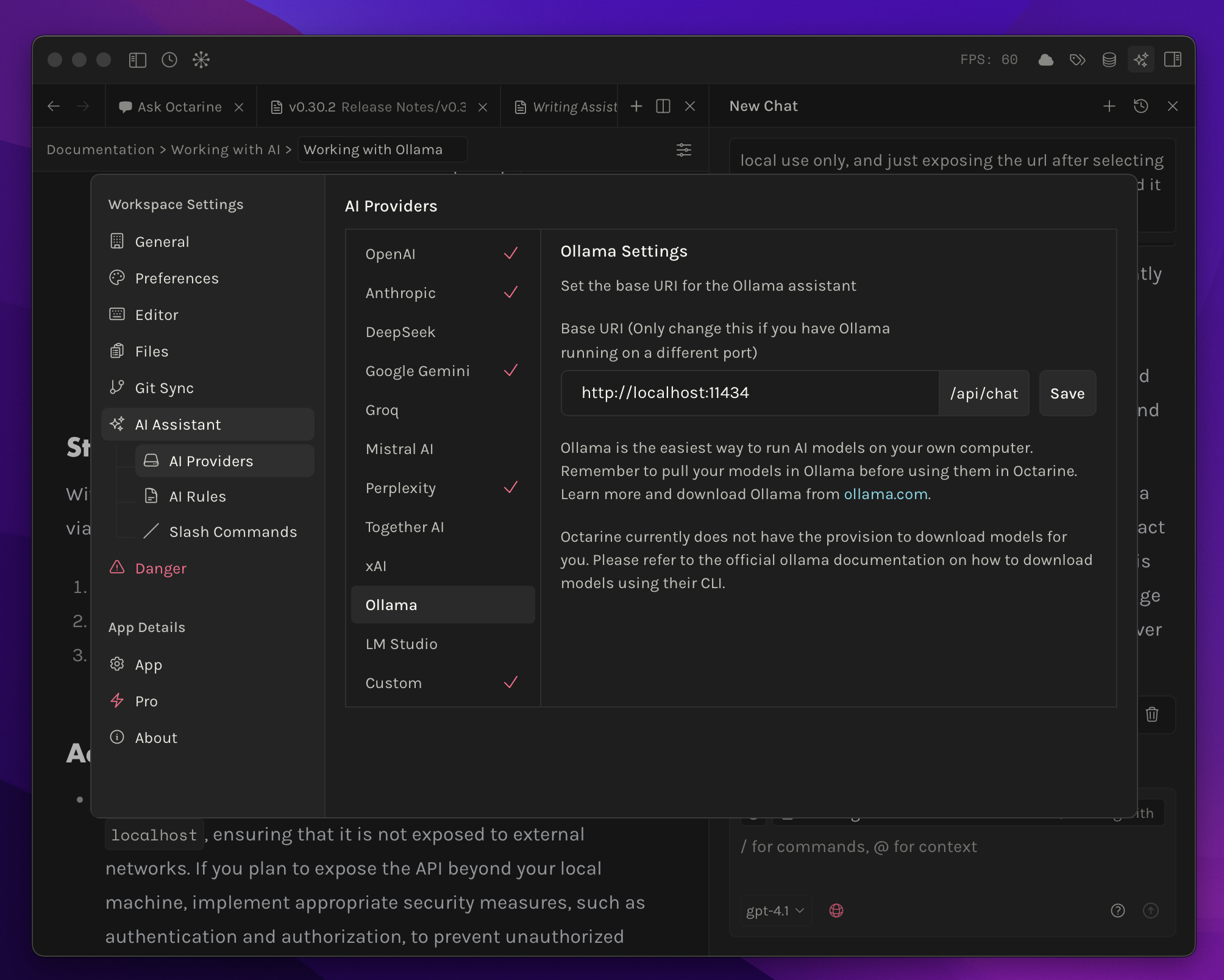
Go to Settings → AI Assistant → AI Providers and click on Ollama. Enter the server URL from the previous step (usually http://localhost:11434) and press Save.
Step 5: Start Using Your Models
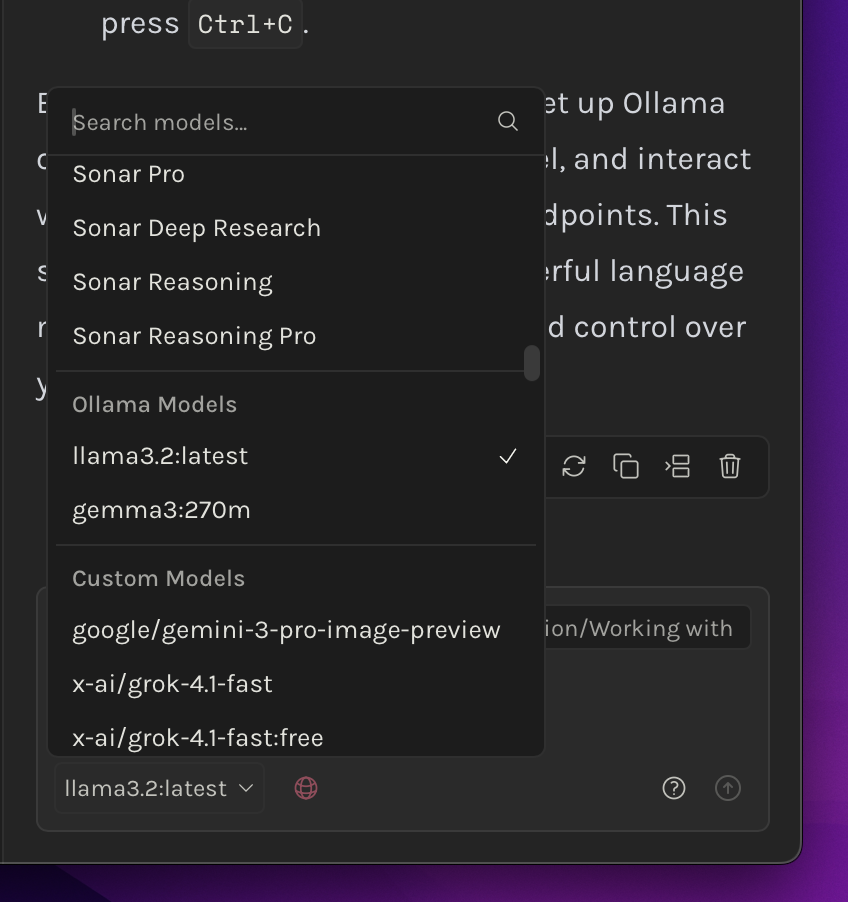
Open the Writing Assistant or Ask Octarine, click the model selector, and look for your Ollama models. Select one and you're ready to go!
A Few Things to Know
The Ollama API only listens on localhost by default, so it's not exposed to the internet—everything stays on your machine.
If you want to see all the models you've downloaded, run ollama list in your terminal. This shows every model currently available.
When you're done, you can stop the Ollama service by going back to the terminal where ollama serve is running and pressing Ctrl+C.
Quick Answers
Can Octarine use Ollama?
Yes. Octarine can connect to Ollama as an AI provider for Writing Assistant and Ask Octarine.
Does Ollama keep AI requests local?
By default, Ollama runs on localhost, so prompts and model responses stay on your machine unless you configure Ollama differently.
What Ollama URL should I enter in Octarine?
Use http://localhost:11434 unless you changed Ollama's default server address.